python scrapy爬虫
总体思路是:
先测试
再进行解析
获取下一层的链接
创建project:
1
| scrapy startproject myproject
|
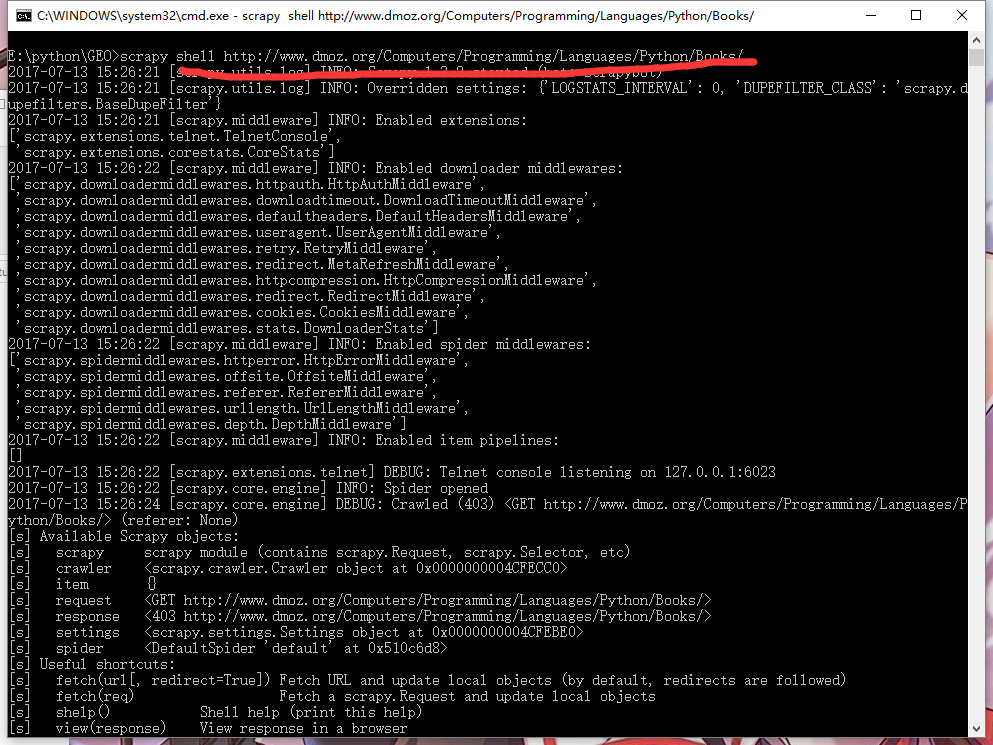
进入cmd:
1
| scrapy shell http://www.dmoz.org/Computers/Programming/Languages/Python/Books/
|

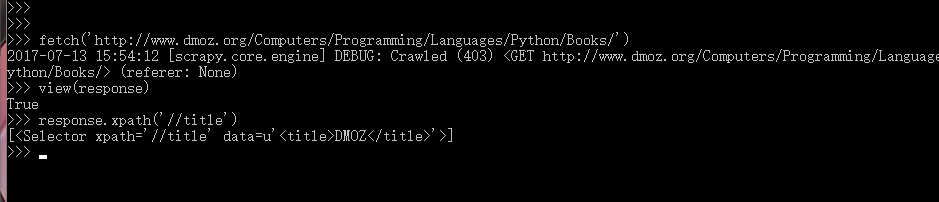
fetch(r”网址”)
view(response)检查网页是否符合要求
1
2
3
| response.xpath("//div[@class='site-title']") 解析网页
response.xpath("//div[contains(@class, 'site-descr')]/text()")[0].extract()
response.xpath("//div[@class='site-title']")[0].xpath("..").xpath("@href")[0].extract() # ..返回上层目录,@属性
|
进入spiders\myproject_spider.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import scrapy
from scrapy import Spider
from scrapy.http import Request
class DmozSpider(Spider):
name='dmoz'
# allowed_domains=["dmoz.org"]
start_urls=[
"http://www.dmoz.org/Computers/Programming/Languages/Python/Books/",
# "http://www.dmoz.org/Computers/Programming/Languages/Python/Resources/" #一开始的页面,第一层页面
]
def start_requests(self): #开始爬虫的网址
for url in self.start_urls:
yield Request(url, callback=self.parse_aaa)
def parse_aaa(self,response): #第一层页面解析方法和要的操作
# def parse_aaa(self,response):
title = response.xpath("//div[@class='site-title']/text()")[0].extract()
description = response.xpath("//div[contains(@class, 'site-descr')]/text()")[0].extract()
link = response.xpath("//div[@class='site-title']")[0].xpath("..").xpath("@href")[0].extract()
# print title
# print description
print link #获取下一层的链接
yield Request(link, callback=self.parse_bbb) #再进行下一层的爬虫和解析
def parse_bbb(self, response):
print "hello"
bb = response.xpath("//a/text()")[0].extract()
print bb
|
cmd测试命令:
参考链接:
https://www.cnblogs.com/wuxl360/p/5567631.html
https://www.xncoding.com/2016/03/10/scrapy-02.html
解析器讲解:
https://www.xncoding.com/2016/03/14/scrapy-04.html
http://cuiqingcai.com/2621.html