php其实很方便简单,但是多了之后就容易乱;
零、工具: (1)IDEA:插件:lombok plugin 、 Mybatis plugin 跳转 、CodeGlance右边栏、Grep console日志区分、JRebel热部署
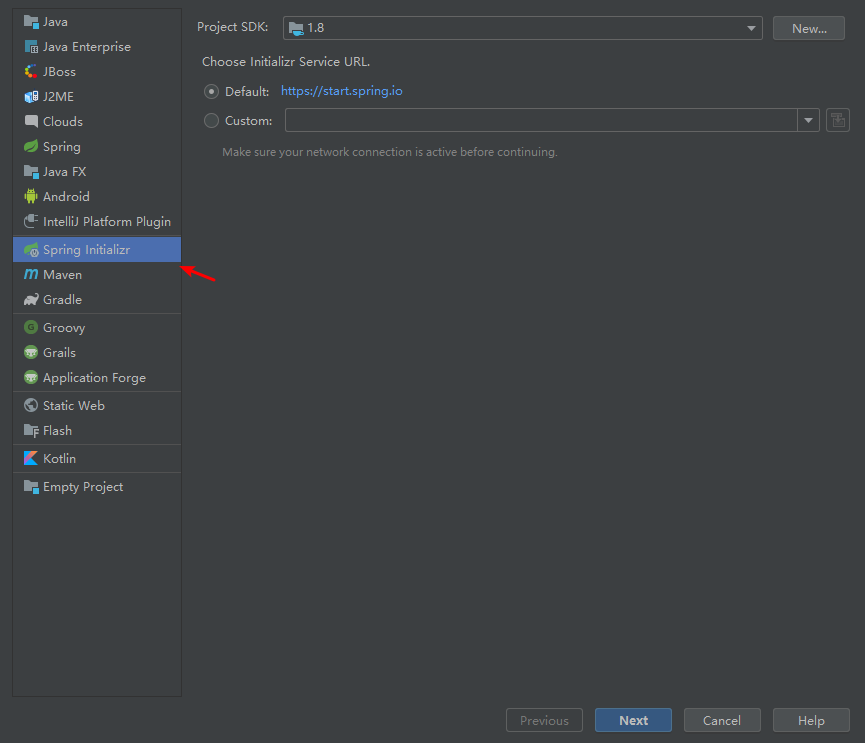
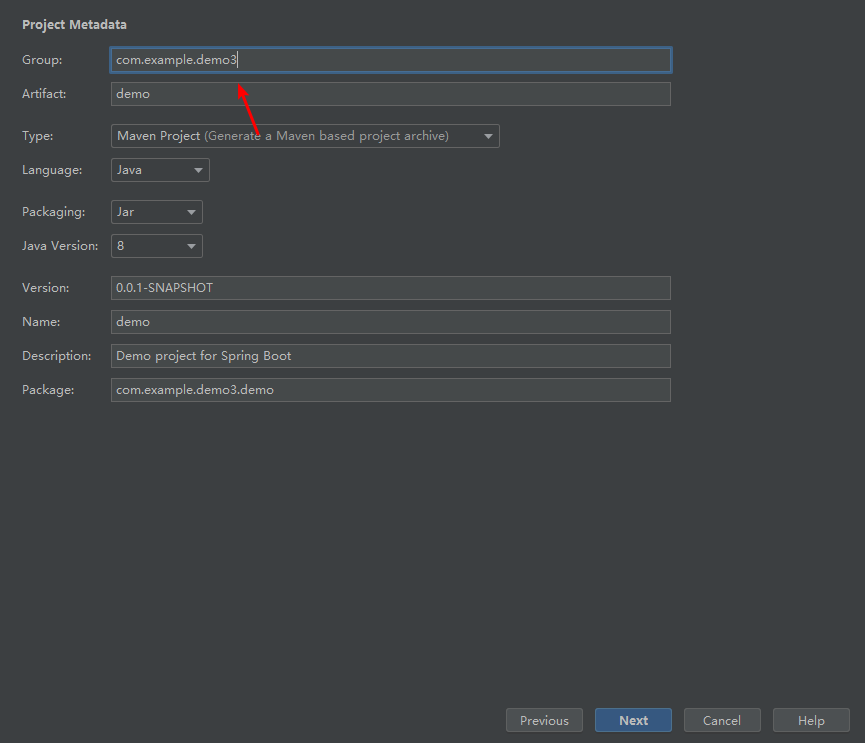
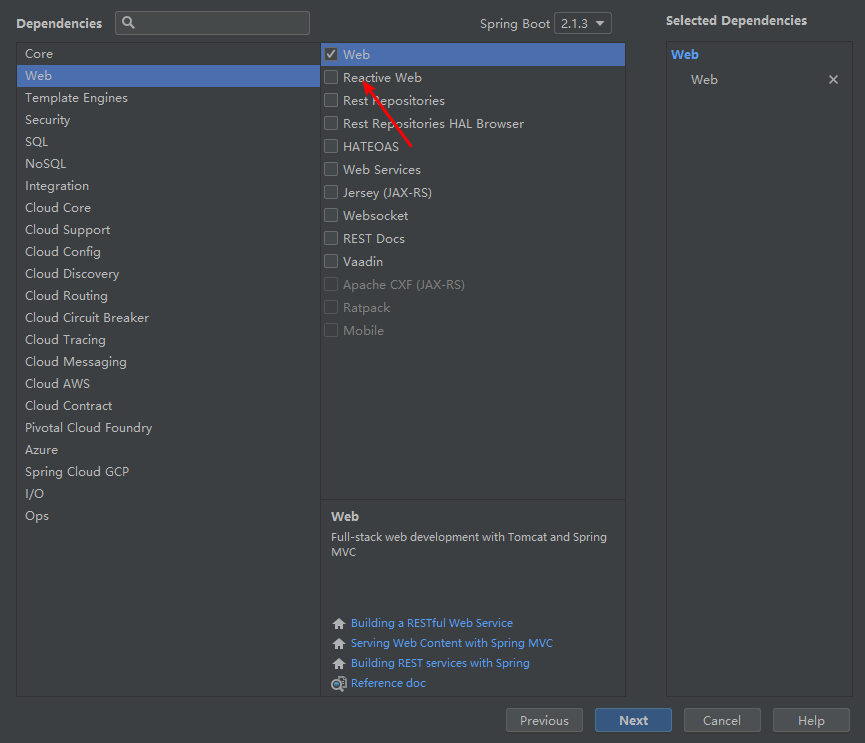
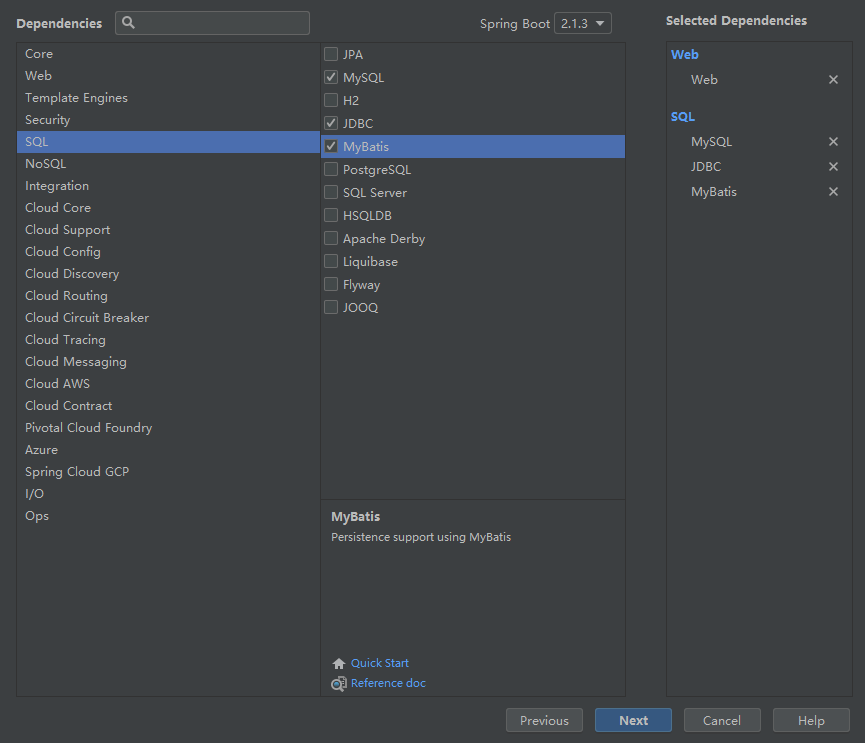
一、新建Springboot项目
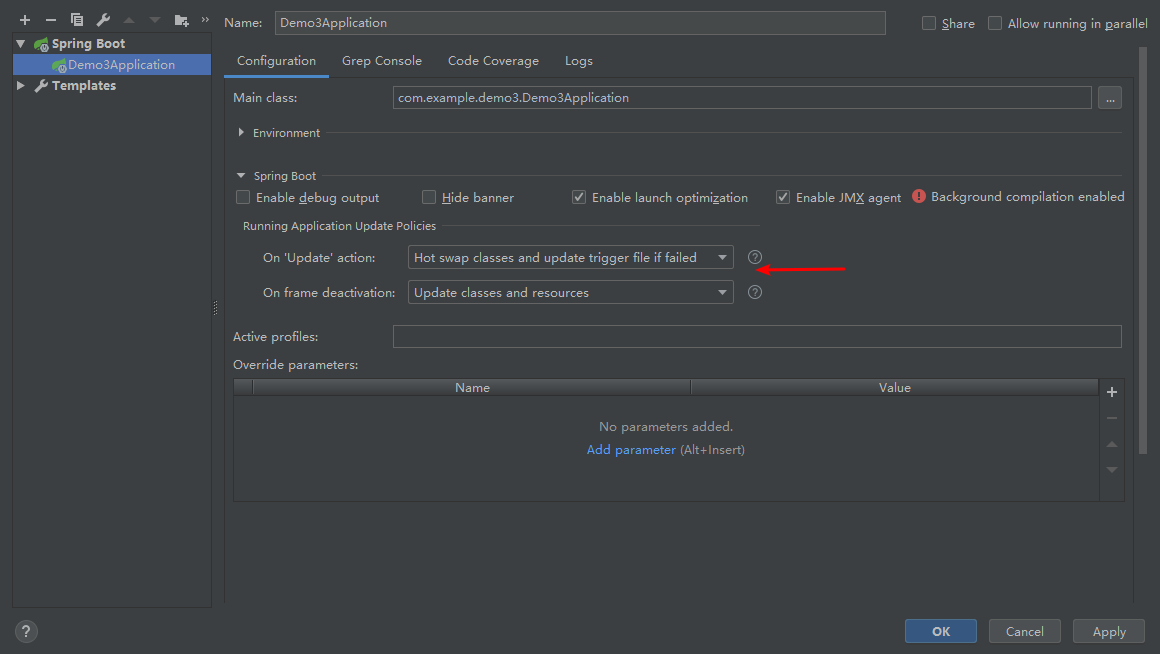
(二)开启热更新: 添加依赖:
1 2 3 4 5 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <optional>true</optional> </dependency>
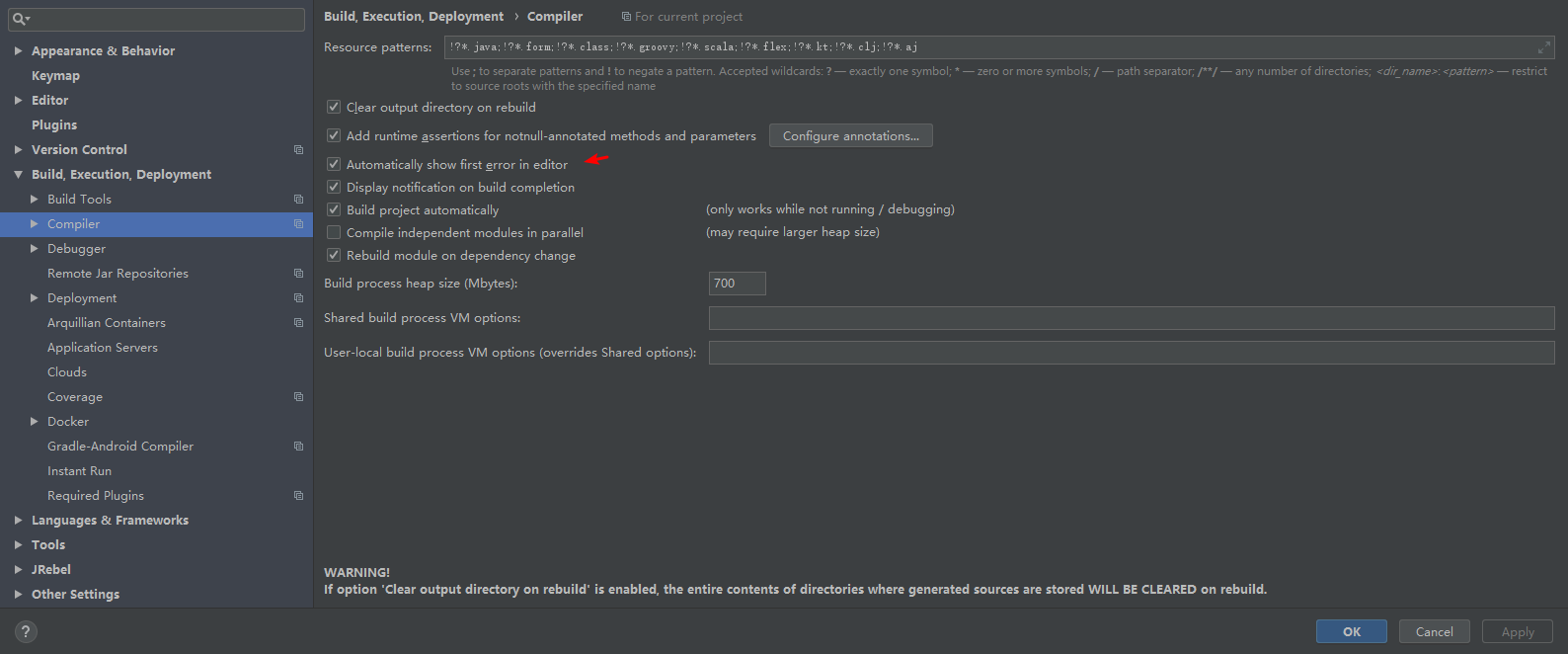
File->setting:
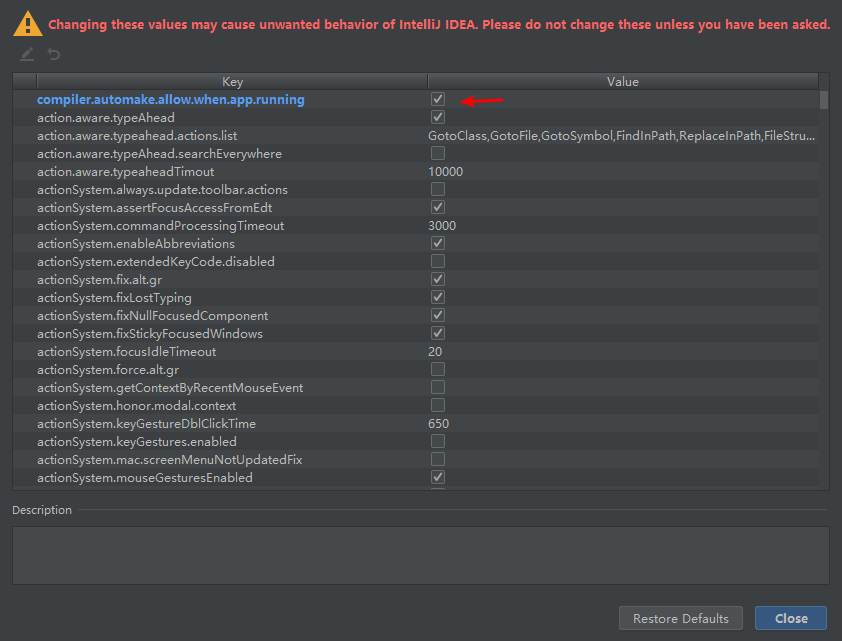
ctrl+alt+shift+/ 就会出来Registry…
顶部菜单- >Edit Configurations
(三)开始 ** pom.xml文件:**
替换数据源:
1 2 3 4 5 6 <!-- https://mvnrepository.com/artifact/com.alibaba/druid --> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.1.12</version> </dependency>
日志:
1 2 3 4 5 <dependency> <groupId>log4j</groupId> <artifactId>log4j</artifactId> <version>1.2.17</version> </dependency>
lombok插件方便写Getter\Setter:
1 2 3 4 5 6 <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <scope>provided</scope> <version>1.16.18</version> </dependency>
** appocation.yml文件 **
注意空格,冒号后需要有一个空格!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 spring: datasource: #数据源配置 url: jdbc:mysql://localhost:3307/mybatis?serverTimezone=GMT%2B8 username: root password: usbw driver-class-name: com.mysql.cj.jdbc.Driver type: com.alibaba.druid.pool.DruidDataSource initialSize: 5 minIdle: 5 maxActive: 20 maxWait: 60000 timeBetweenEvictionRunsMillis: 60000 minEvictableIdleTimeMillis: 300000 validationQuery: SELECT 1 FROM DUAL testWhileIdle: true testOnBorrow: false testOnReturn: false poolPreparedStatements: true # 配置监控统计拦截的filters,去掉后监控界面sql无法统计,'wall'用于防火墙 filters: stat,wall,log4j maxPoolPreparedStatementPerConnectionSize: 20 useGlobalDataSourceStat: true connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500 mybatis: #如果是配置文件版需要加上这个 config-location: classpath:mybatis/mybatis-config.xml 指定全局配置文件位置 mapper-locations: classpath:mybatis/mapper/*.xml 指定sql映射文件位置
** 数据源配置文件: **
config文件夹,新建DruidConfig.java:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 package com.example.demo3.config; @Configuration public class DruidConfig { @ConfigurationProperties(prefix = "spring.datasource") @Bean public DataSource druid() { return new DruidDataSource(); } /** * 配置Druid的监控 * 1、配置一个管理后台的Servlet * @return */ @Bean public ServletRegistrationBean statViewServlet() { ServletRegistrationBean bean = new ServletRegistrationBean(new StatViewServlet(), "/druid/*"); Map<String, String> initParams = new HashMap<>(4); initParams.put("loginUsername", "admin"); initParams.put("loginPassword", "123456"); //默认就是允许所有访问 initParams.put("allow", ""); initParams.put("deny", "192.168.15.21"); bean.setInitParameters(initParams); return bean; } /** * 2、配置一个web监控的filter * @return */ @Bean public FilterRegistrationBean webStatFilter() { FilterRegistrationBean bean = new FilterRegistrationBean(); bean.setFilter(new WebStatFilter()); Map<String, String> initParams = new HashMap<>(1); initParams.put("exclusions", "*.js,*.css,/druid/*"); bean.setInitParameters(initParams); bean.setUrlPatterns(Arrays.asList("/*")); return bean; } }
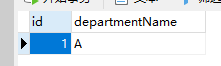
1.创建mysql数据库 department表:
employee表:
注解版: ** 2.创建bean **
1 2 3 4 5 6 7 8 9 package com.example.demo3.bean; import lombok.Getter; import lombok.Setter; @Getter //插件 @Setter public class Department { private Integer id; private String departmentName; }
** 3.创建mapper **
注意点
1 2 3 4 5 6 7 8 9 package com.example.demo3.mapper; import com.example.demo3.bean.Department; import org.apache.ibatis.annotations.*; // 指定這是一個操作數據庫的Mapper @Mapper //注解很重要!!! public interface DepartmentMapper { @Select("select * from department where id=#{id}") public Department getDeptById(Integer id); }
或者统一在Application.java加上:
1 @MapperScan(value="com.example.demo3.mapper")
mapper目录下所有接口都自动添加了mapper注解
** 4.创建Controller **
注意点:
1 2 3 4 5 6 7 8 9 @RestController public class DeptController { @Autowired DepartmentMapper departmentMapper; @GetMapping("/dept/{id}") public Department getDepartment(@PathVariable("id") Integer id){ return departmentMapper.getDeptById(id); } }
配置文件版: 同理:
** (1)创建bean **
** (2)创建mapper: **
** (3)创建xml文件 **
mybatis/mapper添加mybatis-config.xml全局配置文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE configuration PUBLIC "-//mybatis.org//DTD Config 3.0//EN" "http://mybatis.org/dtd/mybatis-3-config.dtd"> <configuration> <settings> <setting name="mapUnderscoreToCamelCase" value="true"/> //表示添加驼峰命名法 </settings> </configuration> mybatis/mapper/EmployeeMapper.xml <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <mapper namespace="com.example.demo3.mapper.EmployeeMapper"> <select id="getEmpById" resultType="com.example.demo3.bean.Employee"> SELECT * FROM employee WHERE id = #{id} </select> </mapper>
appocation.yml文件添加:
namespace需要对应好mapper
** (4)添加controller **
同理:
1 2 3 4 5 6 @Autowired EmployeeMapper employeeMapper; @GetMapping("/emp/{id}") public Employee getEmp(@PathVariable("id") Integer id){ return employeeMapper.getEmpById(id); }
返回为Map格式方便处理数据:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Mapper: List <Map<String,Object>> public interface WerDiffDatasetMapper { List <Map<String,Object>> getCancerdatasetByCancer (String cancer); } xml:resultType="java.util.HashMap" <select id="getCancerdatasetByCancer" resultType="java.util.HashMap"> SELECT distinct dataset FROM geo_sample_dataset WHERE cancer=#{cancer} </select> controller public Map<String, Object> getdataset(@RequestParam(value="cancer") String cancer){ Map <String,Object> modelMap=new HashMap<String,Object>(); List <Map<String,Object>> cancerDatasetlist=werDiffDatasetMapper.getCancerdatasetByCancer(cancer); List<String> cancerDataset = new ArrayList<String>(); for (Map<String, Object> map:cancerDatasetlist ) { for (Map.Entry<String, Object> entry : map.entrySet() //遍历map的key集合 获取对应key的value ) { if ("dataset".equals(entry.getKey())) { cancerDataset.add(String.valueOf(entry.getValue())); } } } modelMap.put("datasetinfo",cancerDataset); return modelMap; }
List <Map<String,Object>> cancerDatasetlist=werDiffDatasetMapper.getCancerdatasetByCancer(cancer);
新建List <Map<String,Object>>接收数据
log4j初始配置: resources文件夹下,创建文件:log4j.properties
更改最后一行包名:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 log4j.rootLogger=debug, stdout, R log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%5p - %m%n log4j.appender.R=org.apache.log4j.RollingFileAppender log4j.appender.R.File=firestorm.log log4j.appender.R.MaxFileSize=100KB log4j.appender.R.MaxBackupIndex=1 log4j.appender.R.layout=org.apache.log4j.PatternLayout log4j.appender.R.layout.ConversionPattern=%p %t %c - %m%n #log4j.logger.自己的包名=DEBUG log4j.logger.com.example.demo3=DEBUG
mysql 联合查询: ** 一对多:使用:collection **
gene2Peaks 字表 ,加上多的Set:
1 private Set <Gene2Peak> gene2Peaks;
1 <collection property="gene2Peaks" ofType="com.atguigu.springboot.bean.Gene2Peak">
1 2 3 4 5 6 public class GeneInfo { private String genename; private Integer geneid; private Set <Gene2Peak> gene2Peaks; }
** 一对一:不用set,使用association **
1 <association property="peakInfos" javaType="com.atguigu.springboot.bean.PeakInfo">
1 2 3 4 public class Gene2Peak { private Integer g2ppeakid; private PeakInfo peakInfos; }
https://www.cnblogs.com/yansum/p/5819973.html
返回嵌套的:
1 <select id="getSearch" resultMap="SearchMapper">
直接返回:list map
1 <select id="getSearch" resultType="java.util.HashMap">
完整:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 <mapper namespace="com.atguigu.springboot.mapper.SearchMapper"> <resultMap type="com.atguigu.springboot.bean.GeneInfo" id="SearchMapper"> <id column="geneid" property="geneid"/> <result column="genename" property="genename"/> <result column="strand" property="strand"/> <result column="descr" property="descr"/> <result column="Entrezid" property="Entrezid"/> <result column="Ensemblid" property="Ensemblid"/> <result column="Uniprotid" property="Uniprotid"/> <collection property="gene2Peaks" ofType="com.atguigu.springboot.bean.Gene2Peak"> <id column="g2ppeakid" property="g2ppeakid"/> <result column="g2pgeneid" property="g2pgeneid"/> <association property="peakInfos" javaType="com.atguigu.springboot.bean.PeakInfo"> <id column="peakid" property="peakid"></id> <id column="seq" property="seq"></id> <id column="num" property="num"></id> </association> </collection> </resultMap> <select id="getSearch" resultType="java.util.HashMap"> SELECT geneinfo.*,peakinfo.* FROM geneinfo ,gene2peak,peakinfo where geneid=g2pgeneid AND peakid = g2ppeakid <if test="search != ''"> AND genename LIKE '%${search}%' OR Entrezid LIKE '%${search}%' OR strand LIKE '%${search}%' </if> <if test="length != ''"> LIMIT #{start},#{length} </if> </select> </mapper>